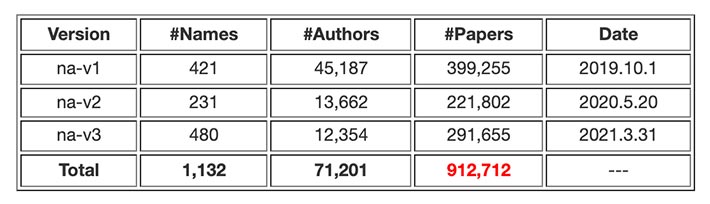
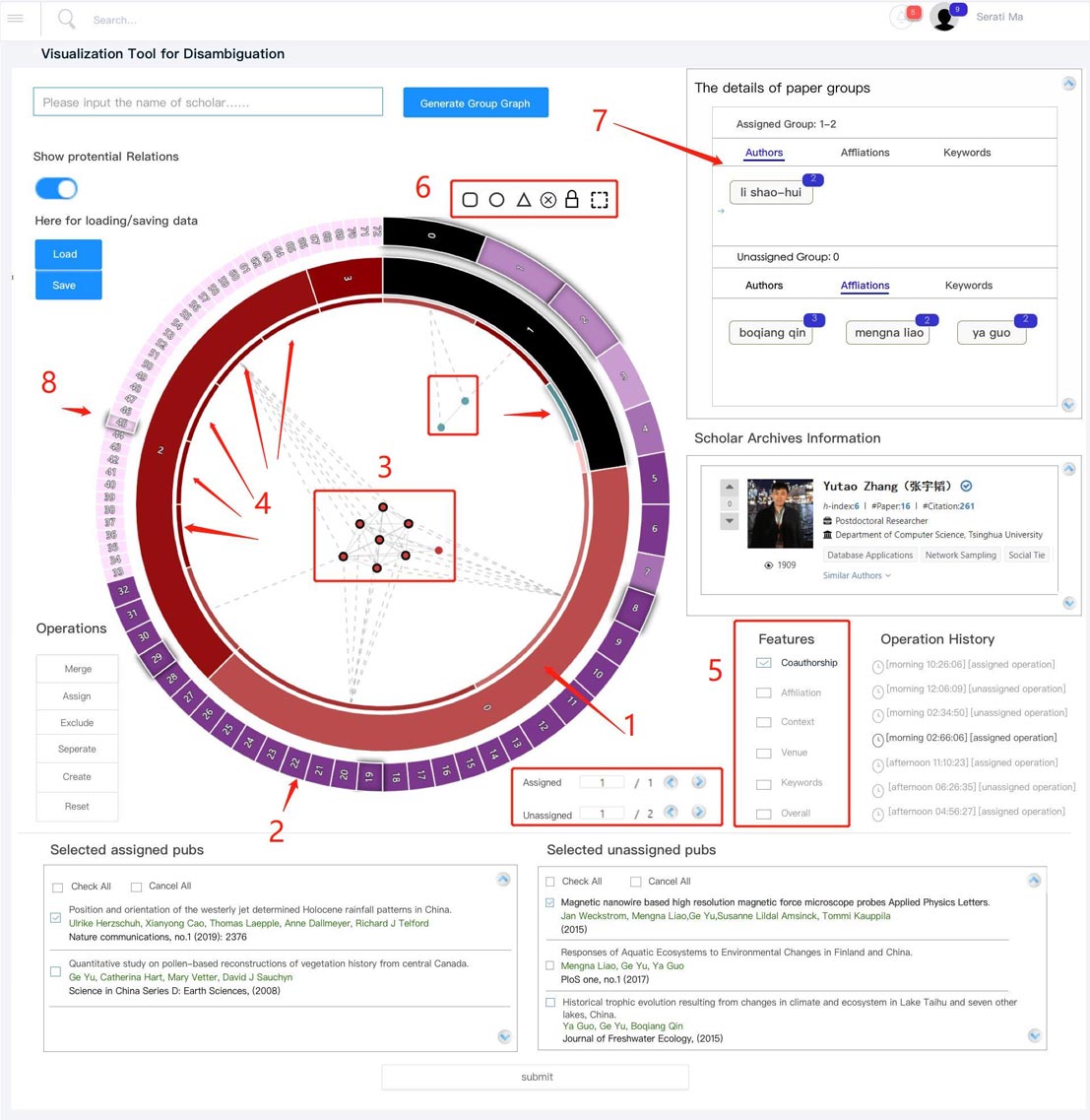
If you think WhoIsWho is helpful to you, please cite the following papers,
@article{chen2023web,
title={Web-Scale Academic Name Disambiguation: the WhoIsWho Benchmark, Leaderboard, and Toolkit},
author={Chen, Bo and Zhang, Jing and Zhang, Fanjin and Han, Tianyi and Cheng, Yuqing and Li, Xiaoyan and Dong, Yuxiao and Tang, Jie},
journal={arXiv preprint arXiv:2302.11848},
year={2023}}
@inproceedings{tang2008arnetminer,
title={Arnetminer: extraction and mining of academic social networks},
author={Tang, Jie and Zhang, Jing and Yao, Limin and Li, Juanzi and Zhang, Li and Su, Zhong},
booktitle={Proceedings of the 14th ACM SIGKDD international
conference on Knowledge discovery and data mining},
pages={990--998},
year={2008}
}